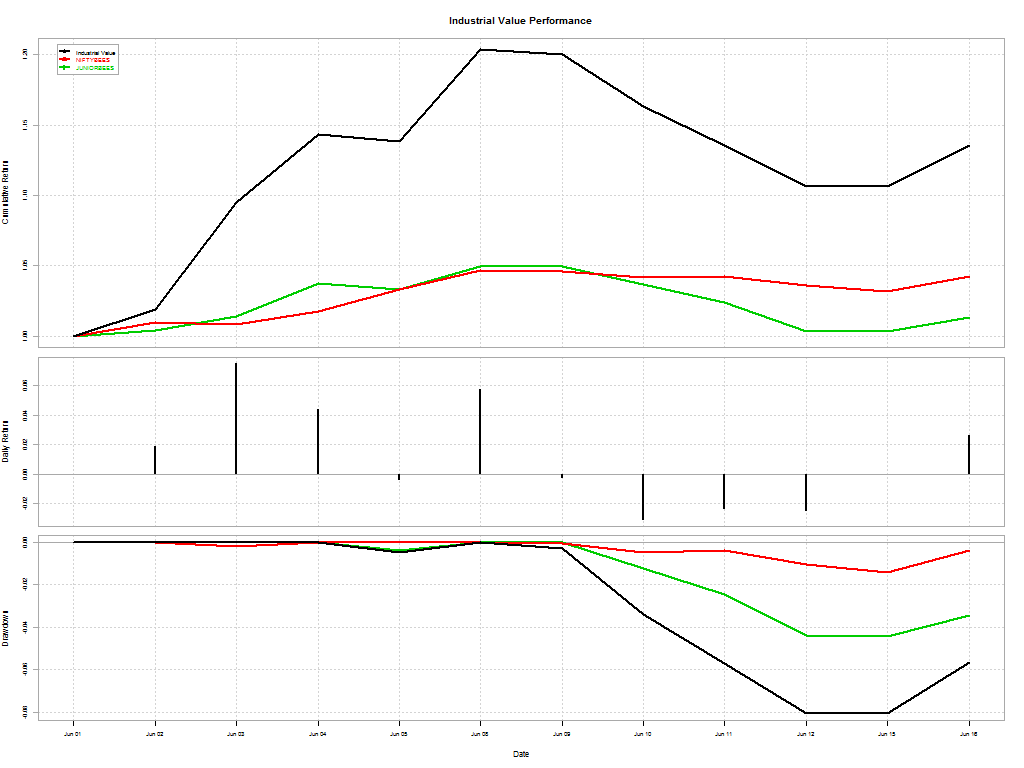
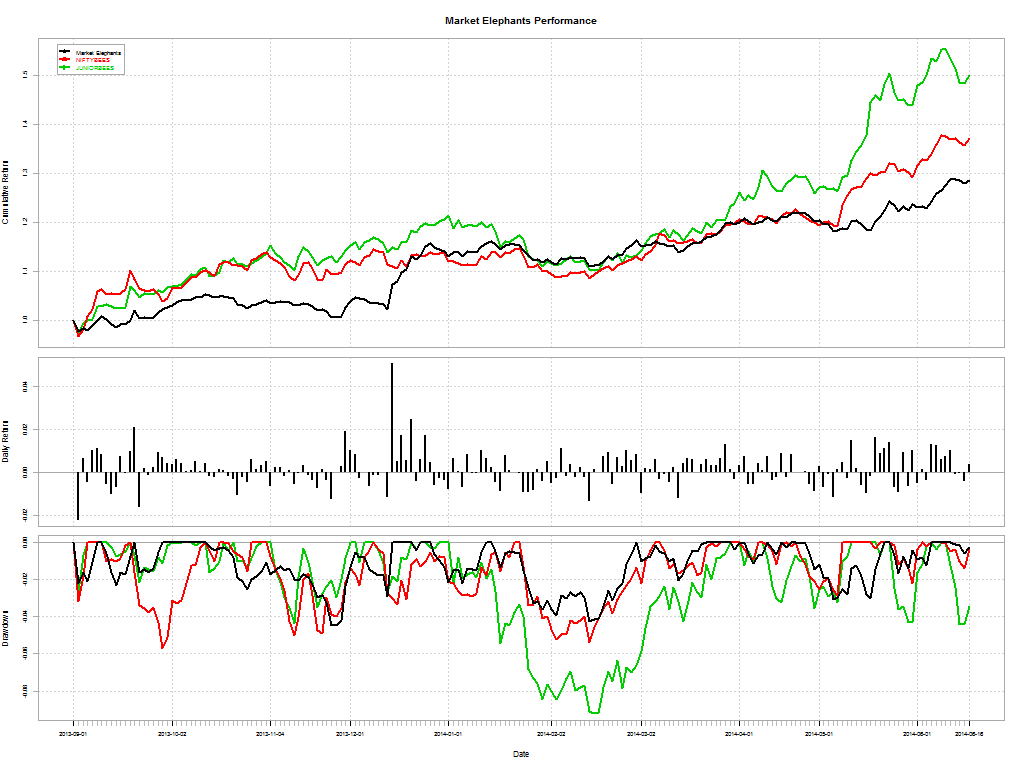
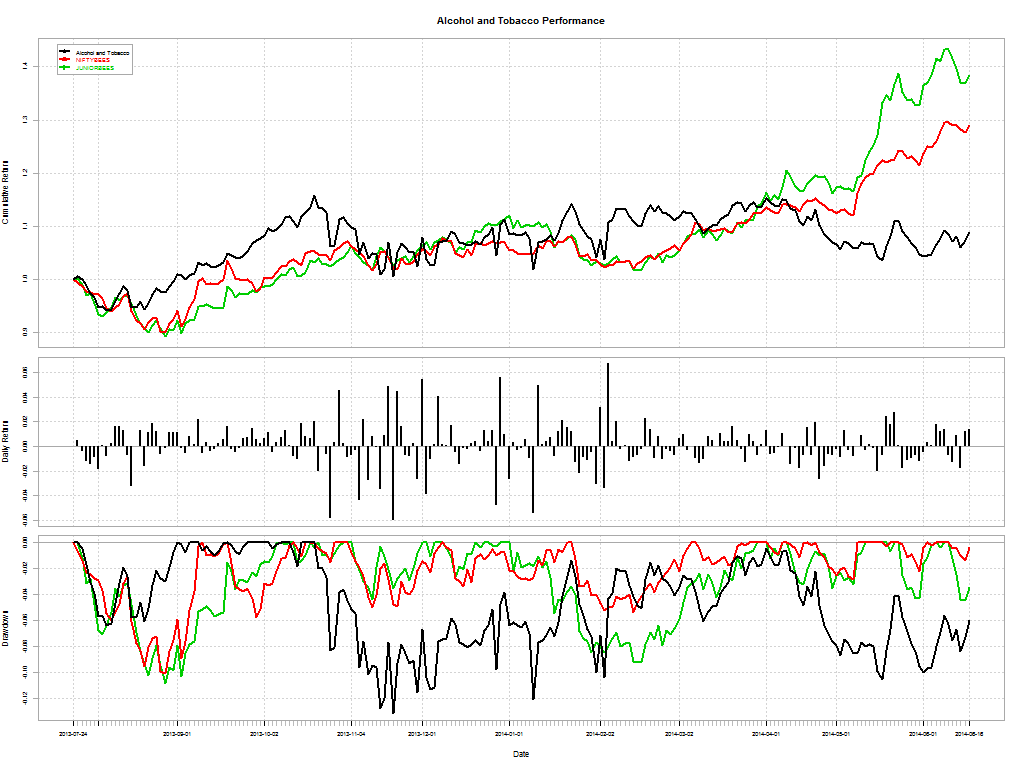
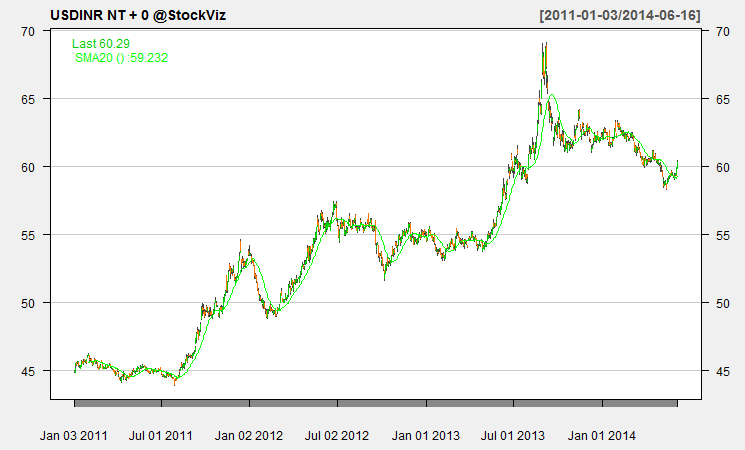
From Why Inexperienced Investors Do Not Learn: They Do Not Know Their Past Portfolio Performance (Glaser, Weber)
A necessary condition to learn is that investors actually know what happened in the past and that the views of the past are not biased. Investors are hardly able to give a correct estimate of their own past realized stock portfolio performance. People overrate themselves. On average, investors think, that they are better than others.
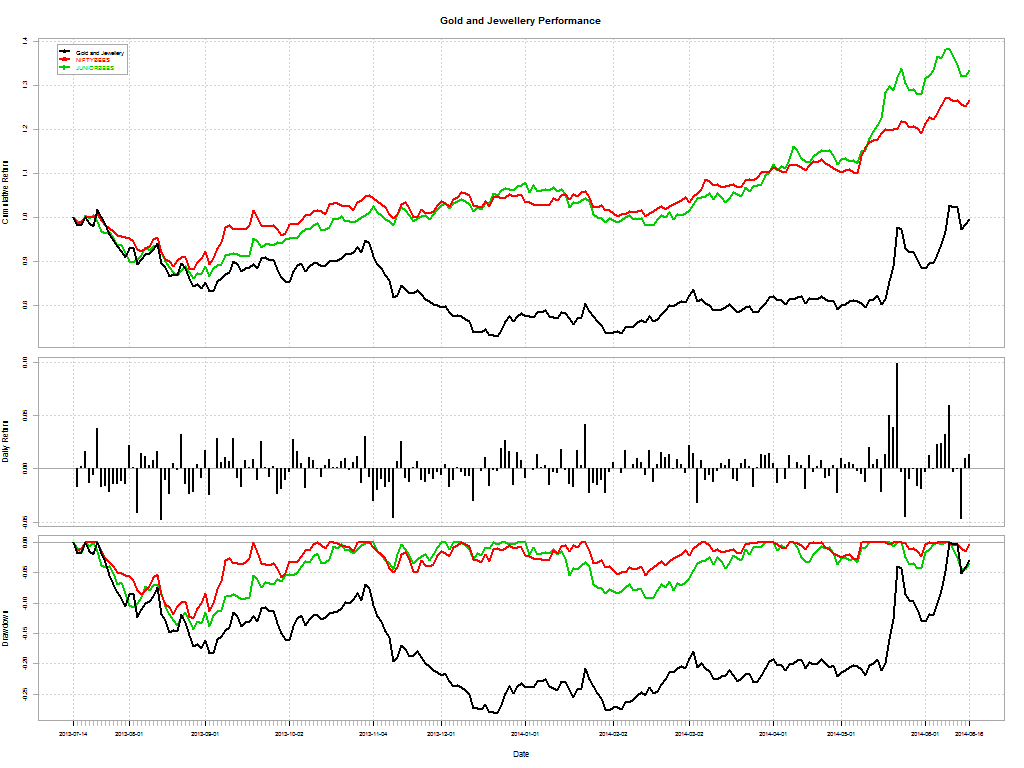
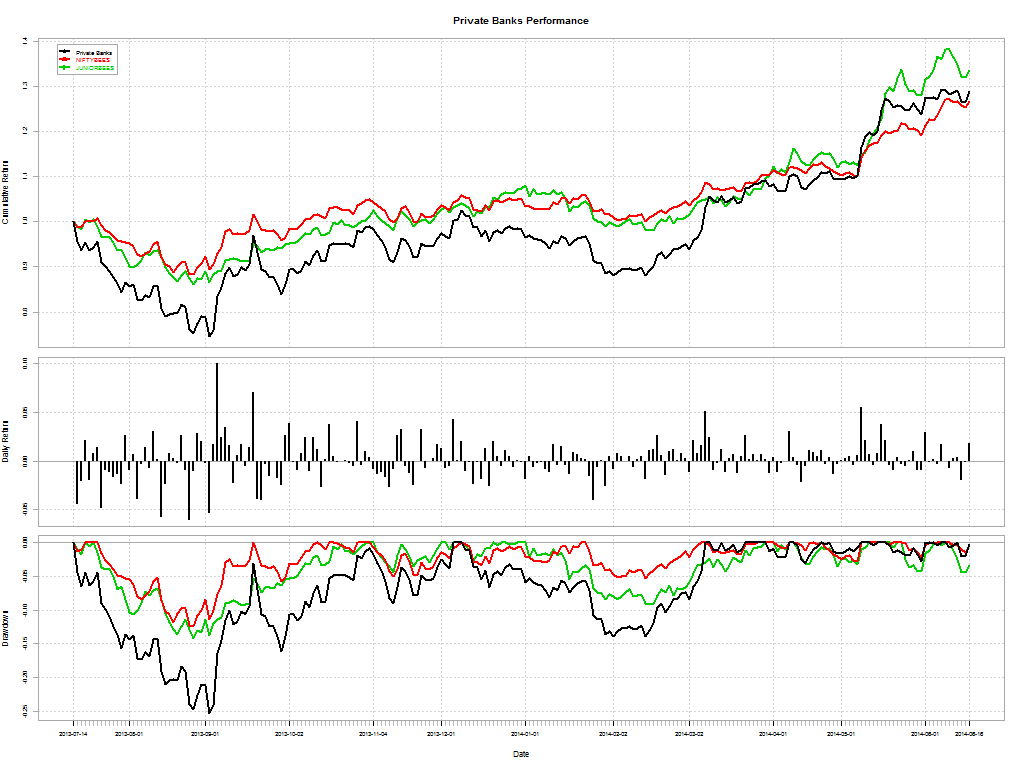
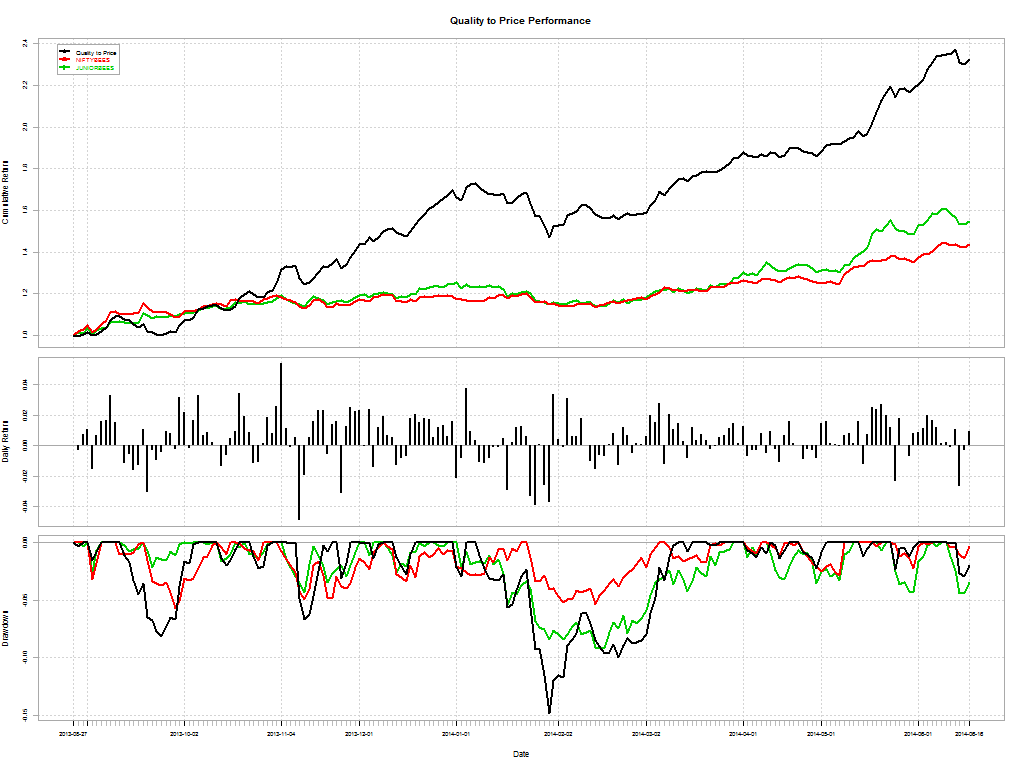
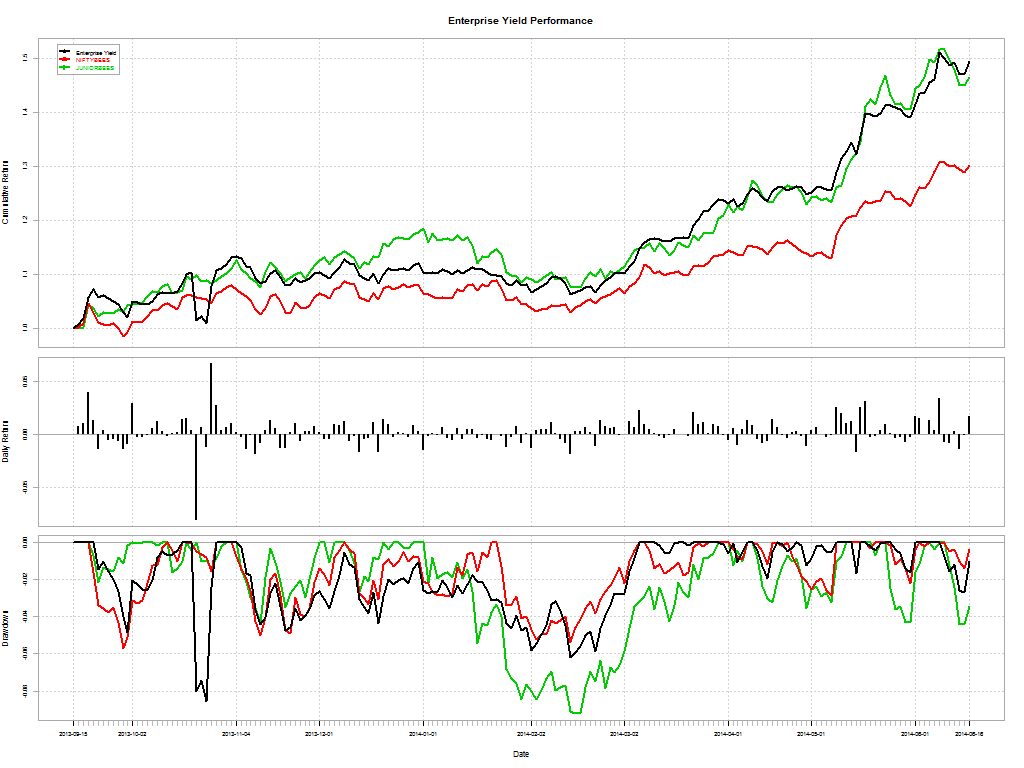
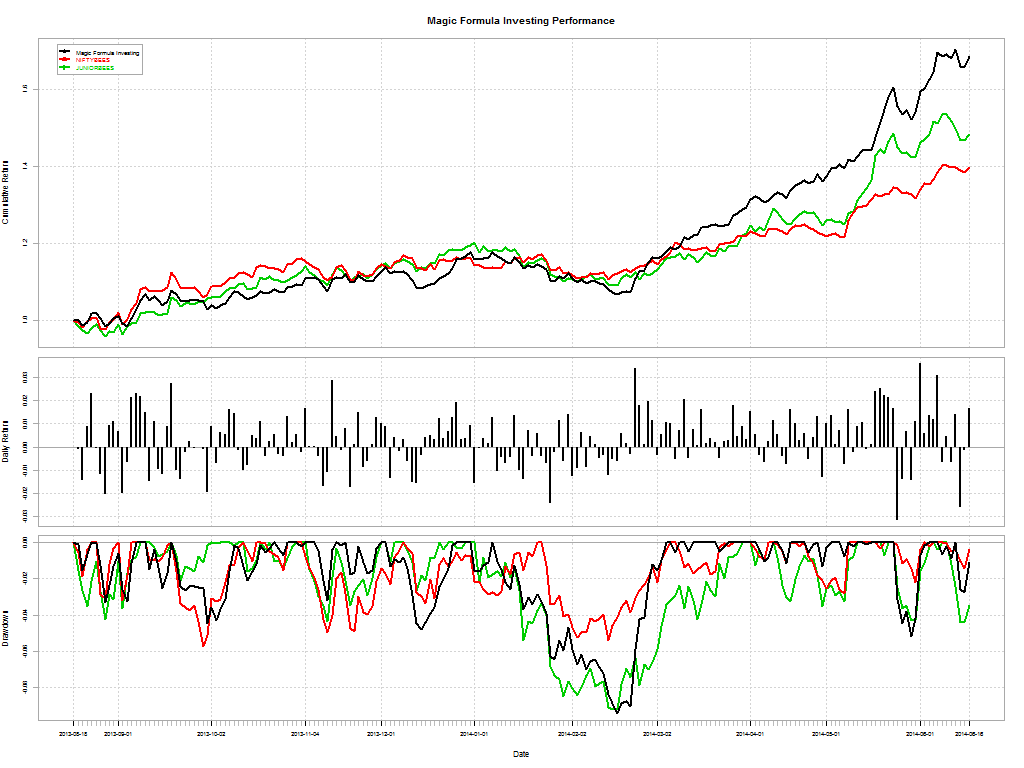
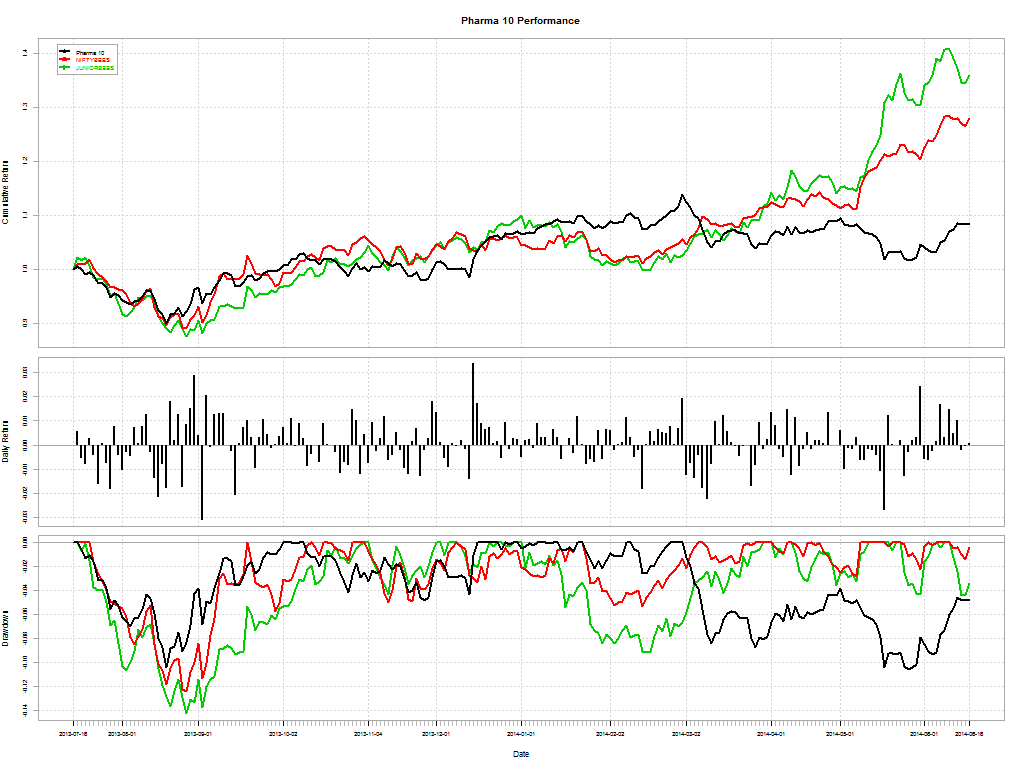
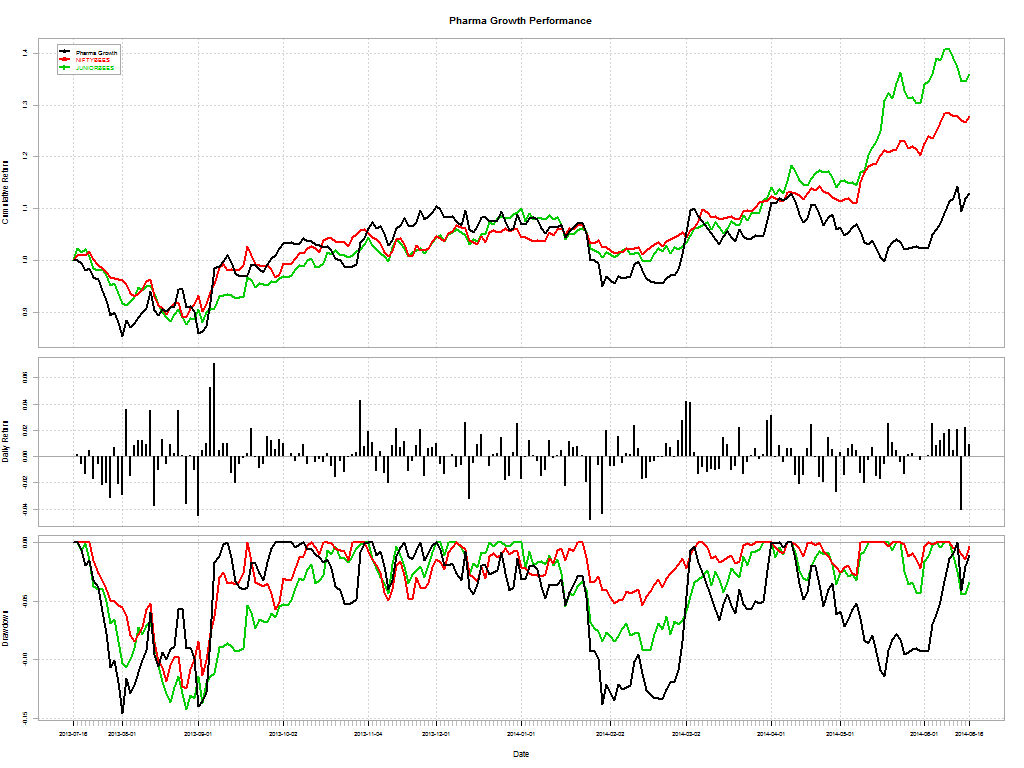
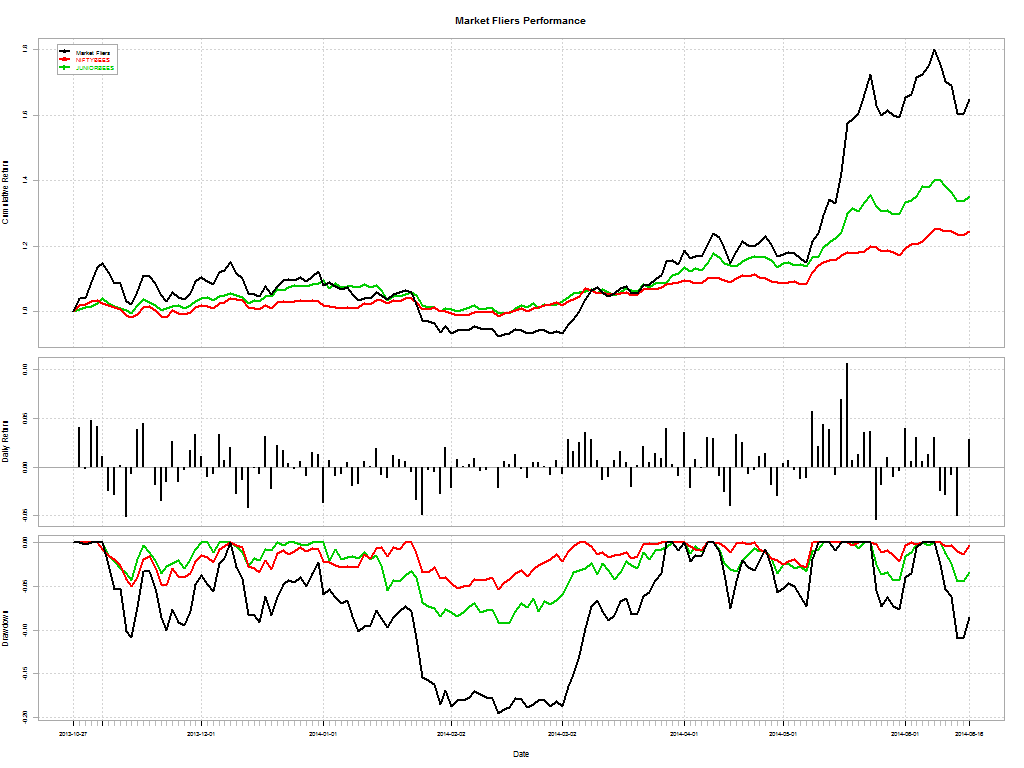
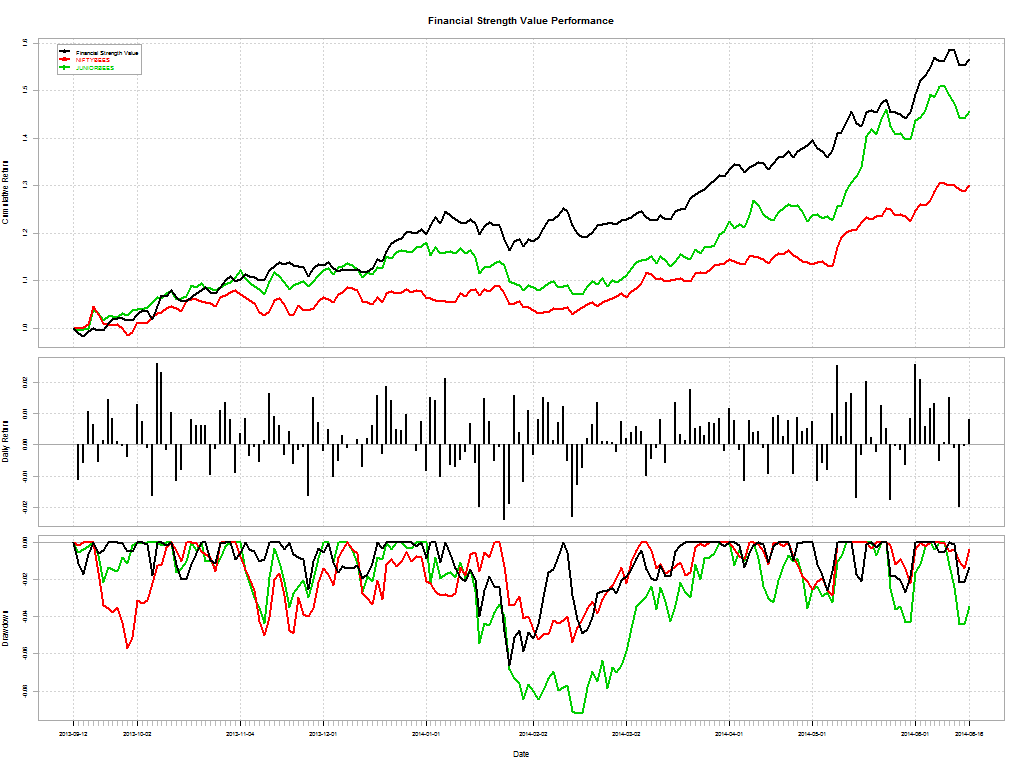
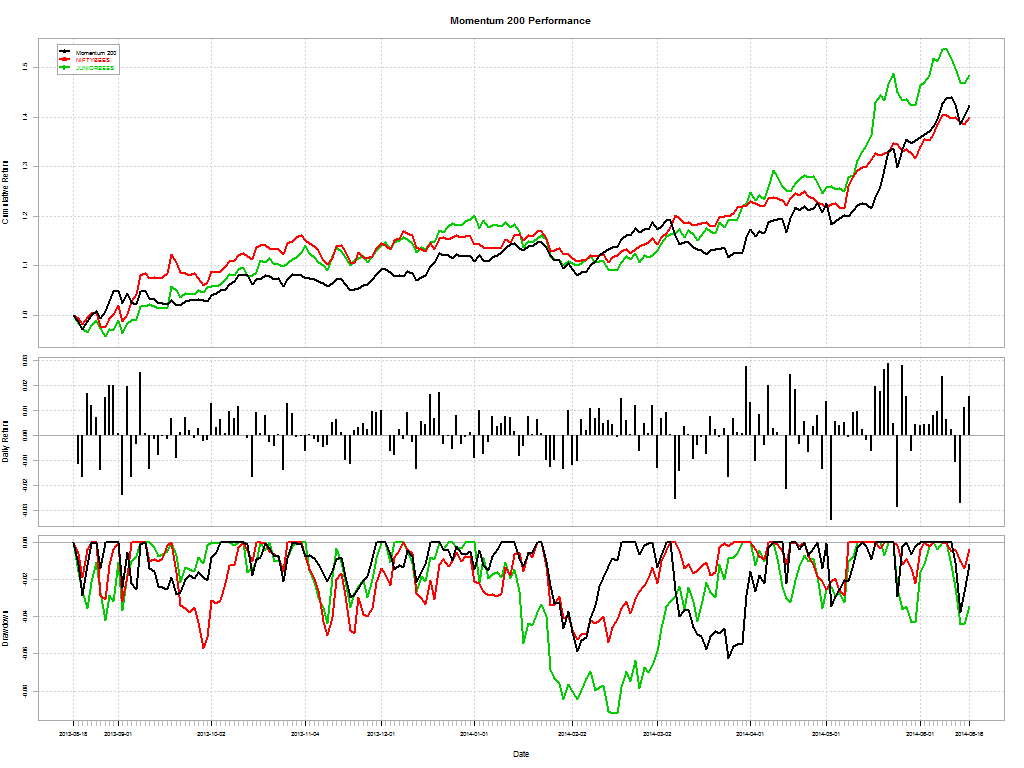
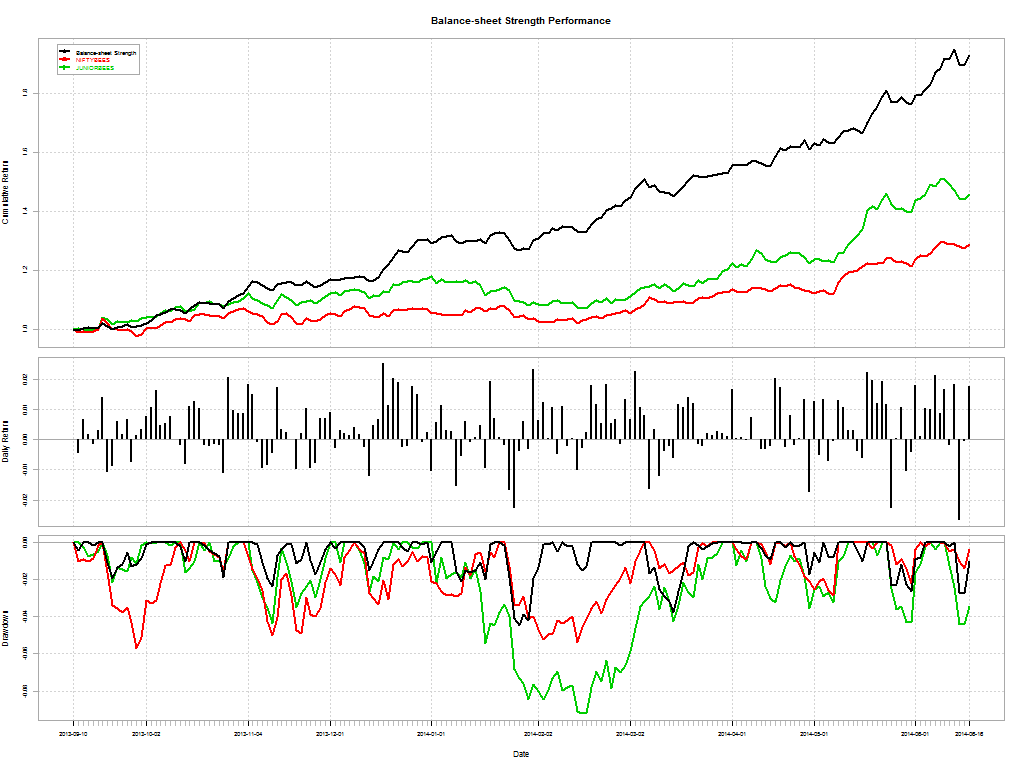
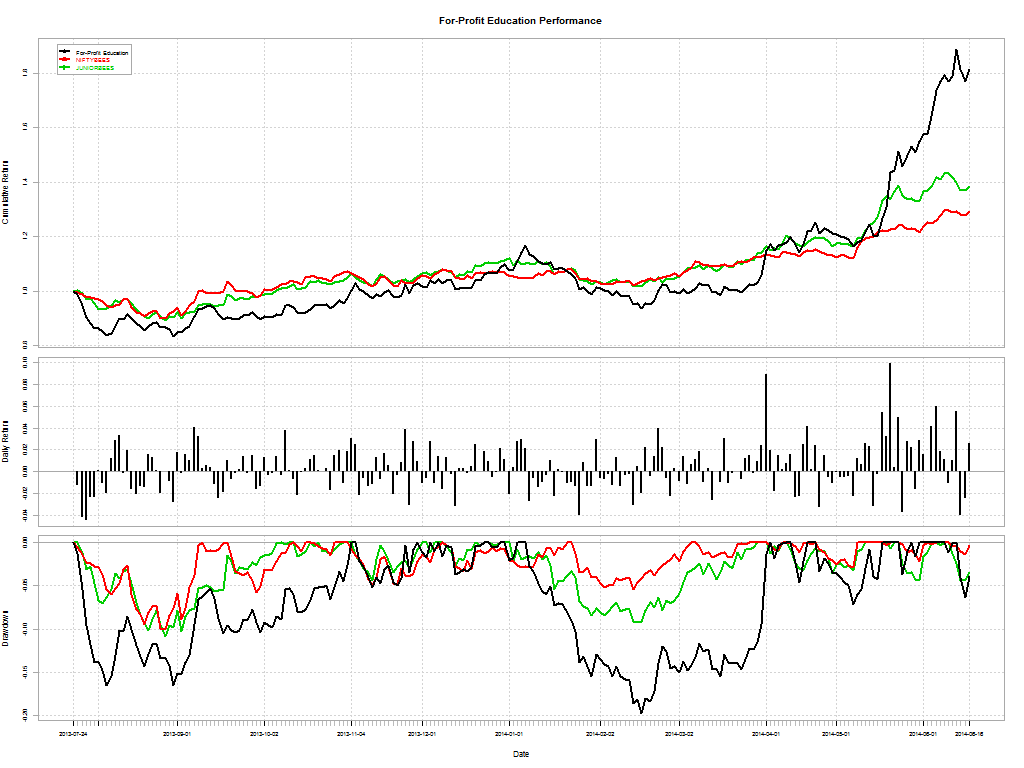
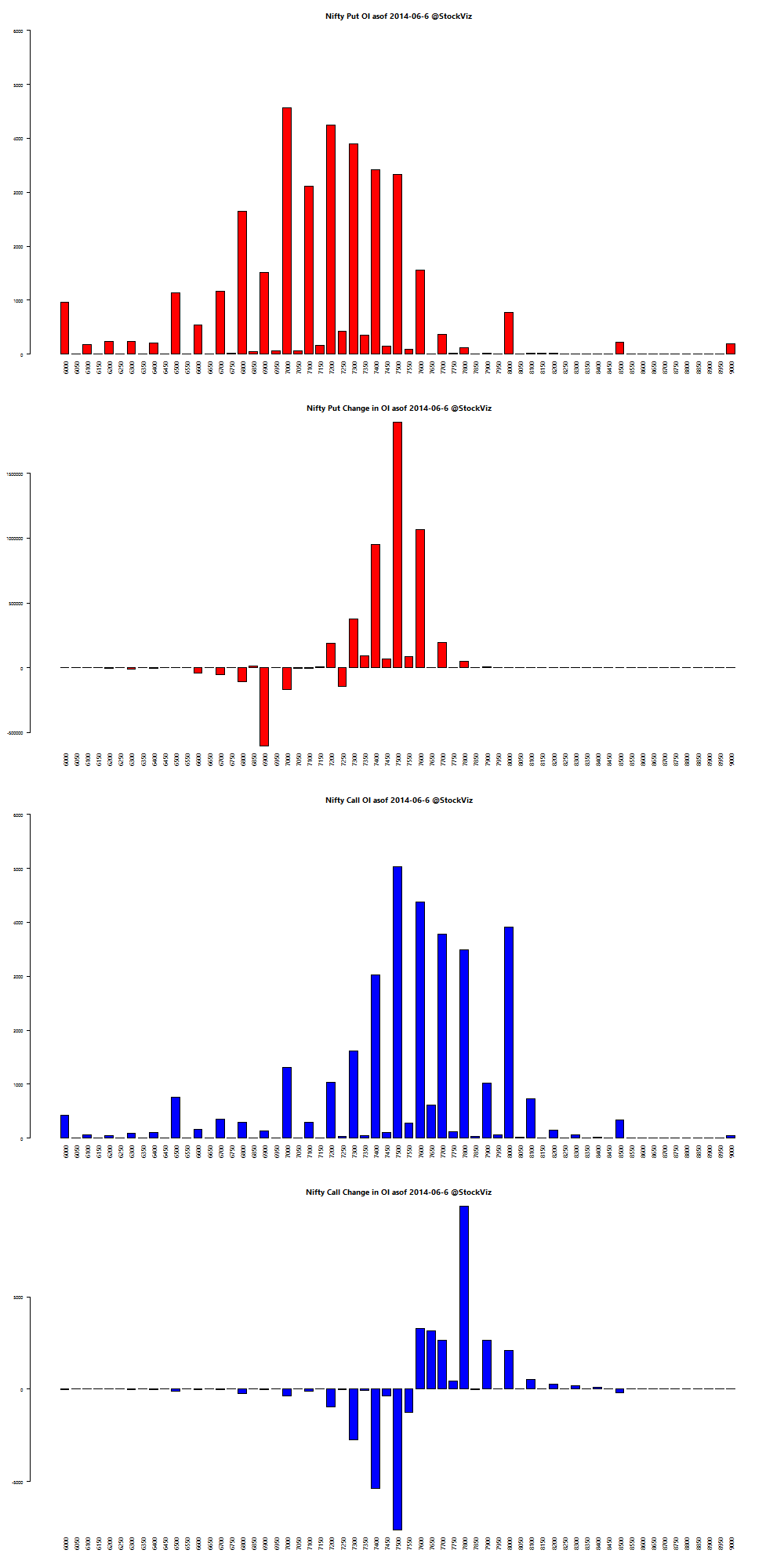
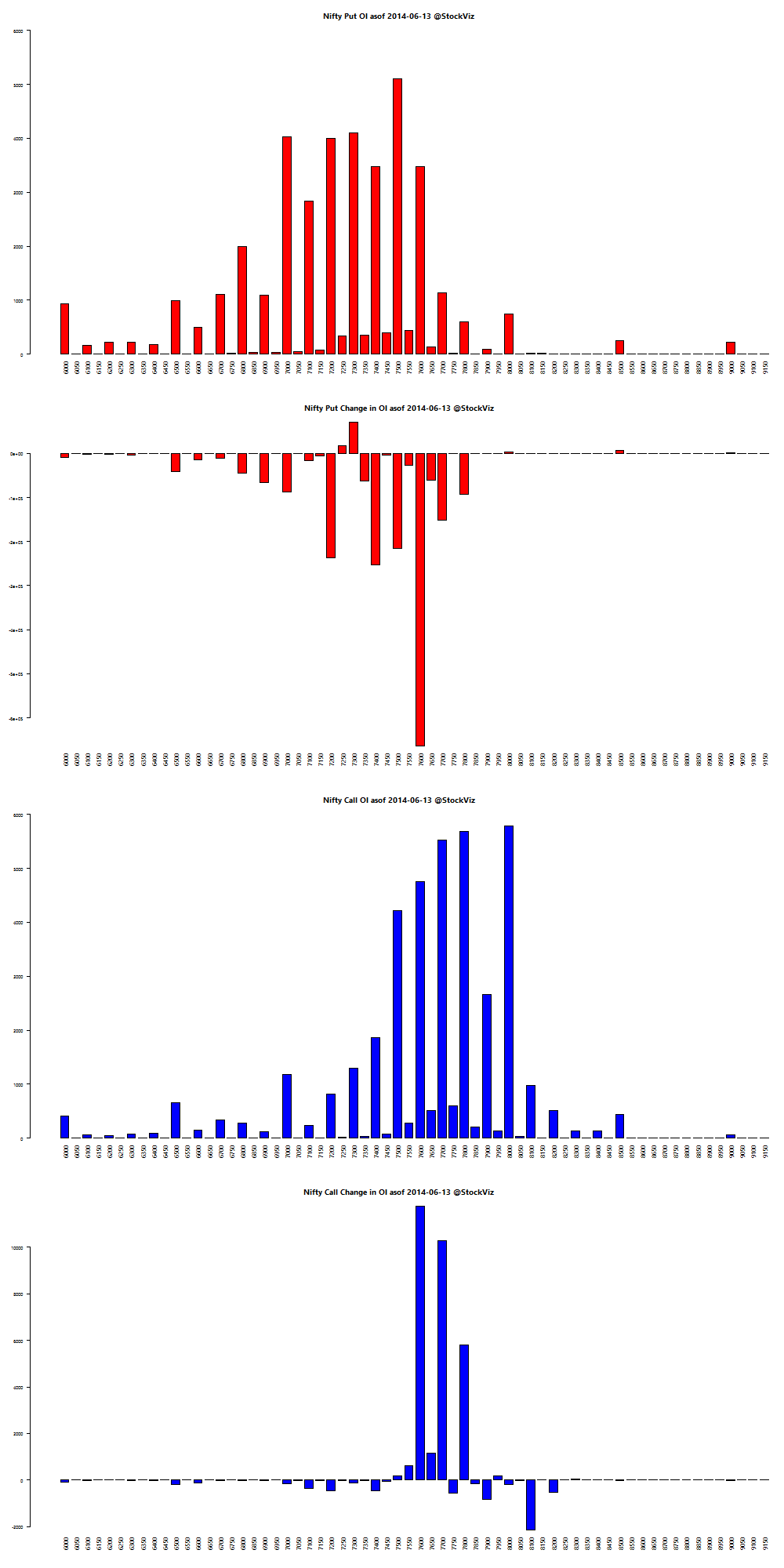
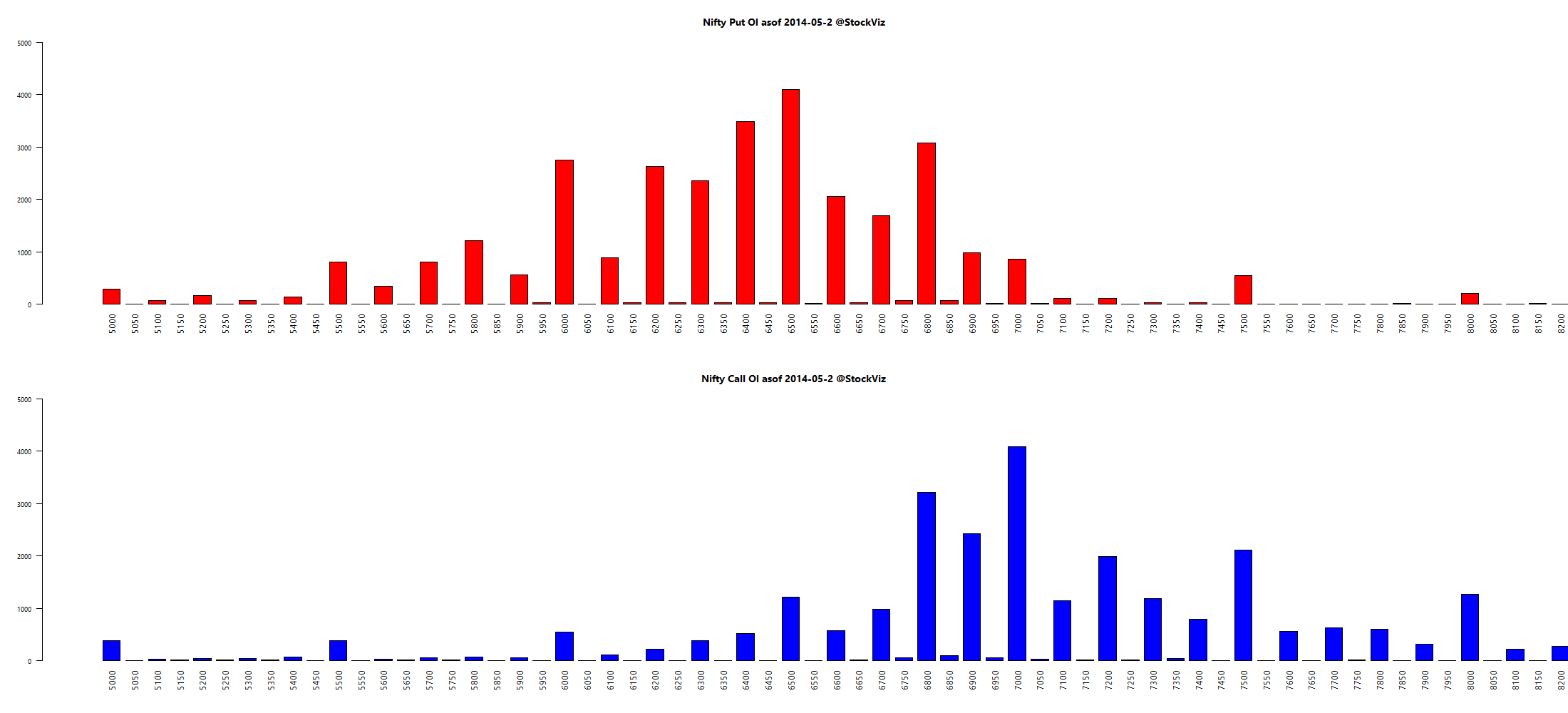
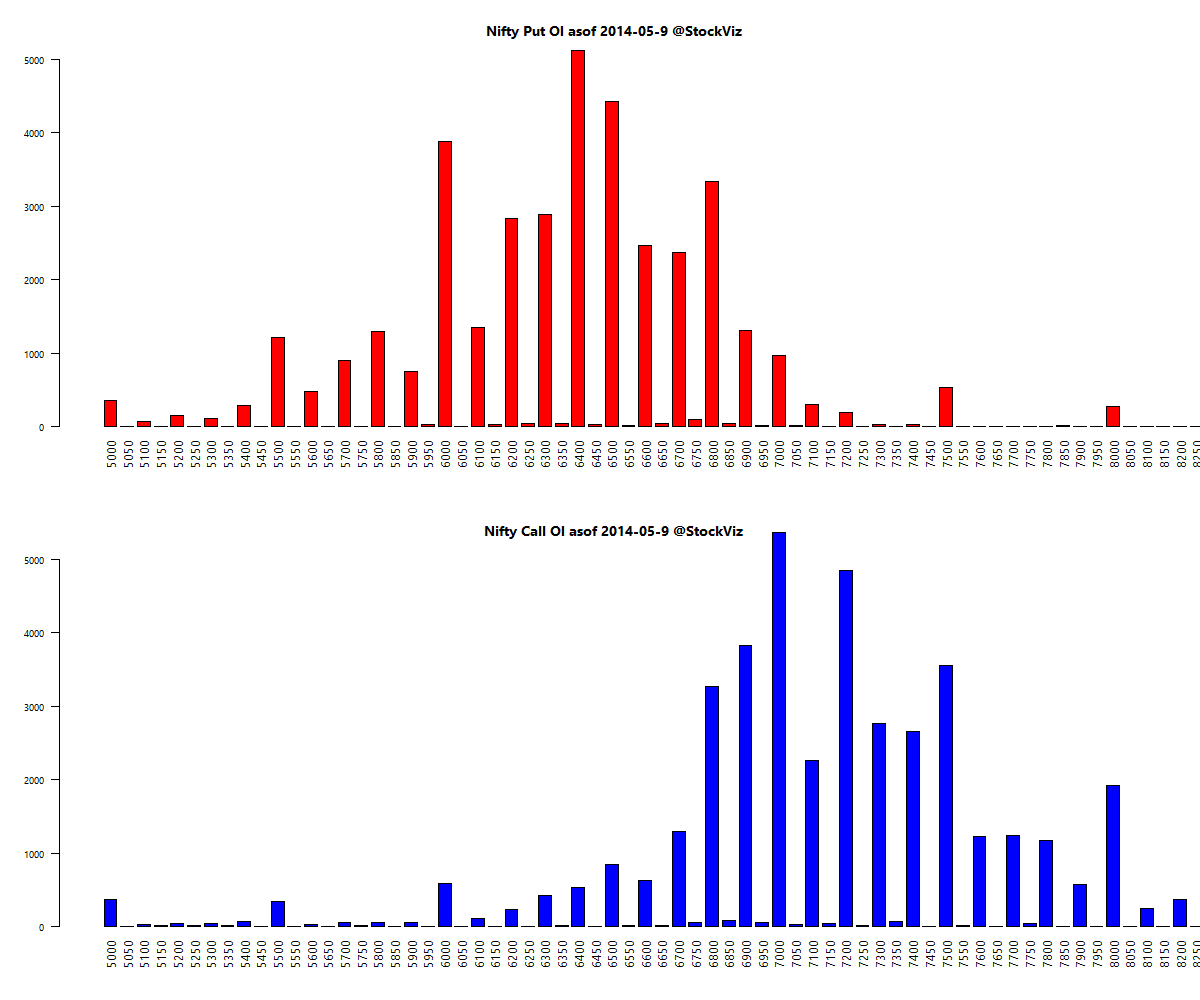
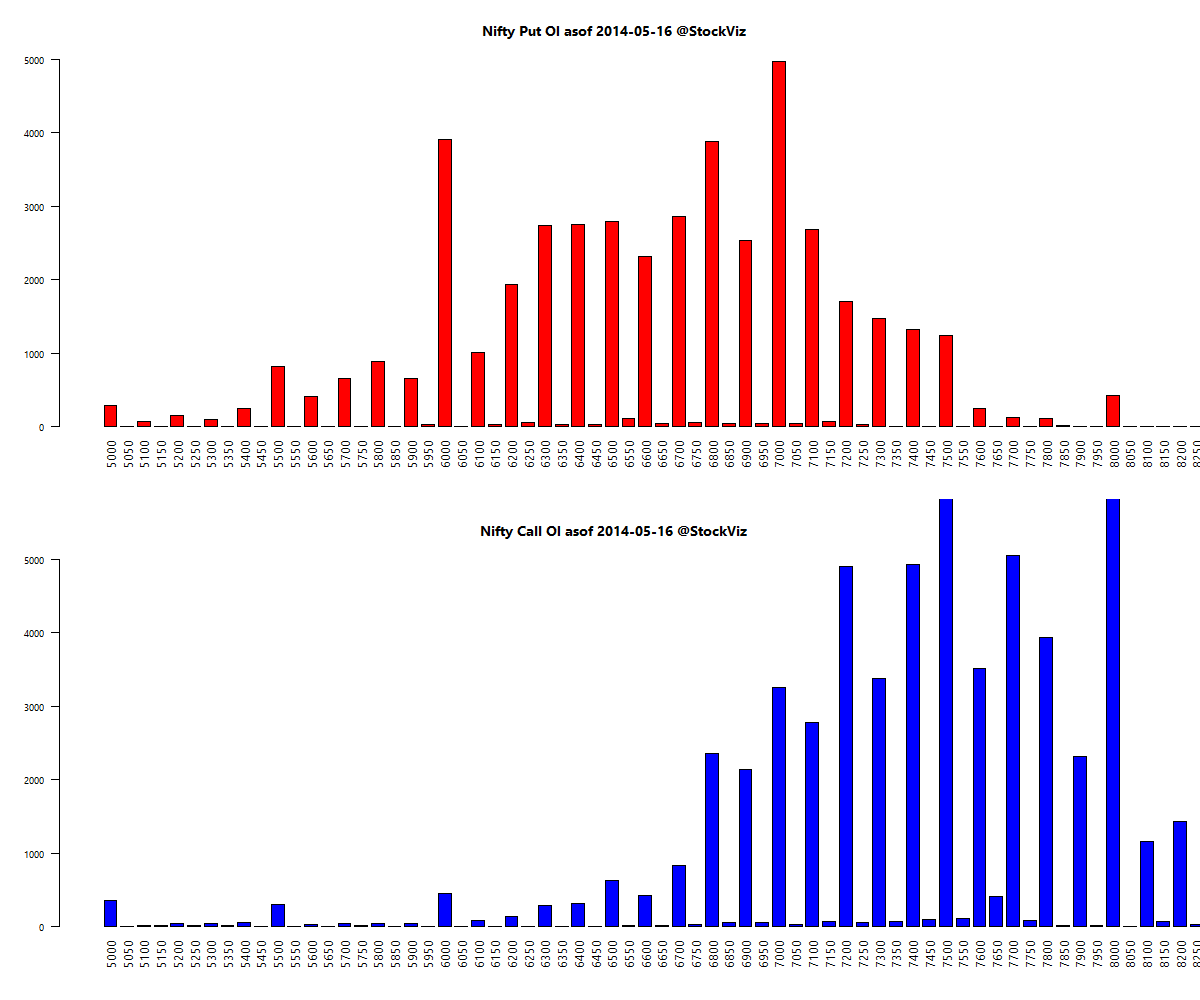
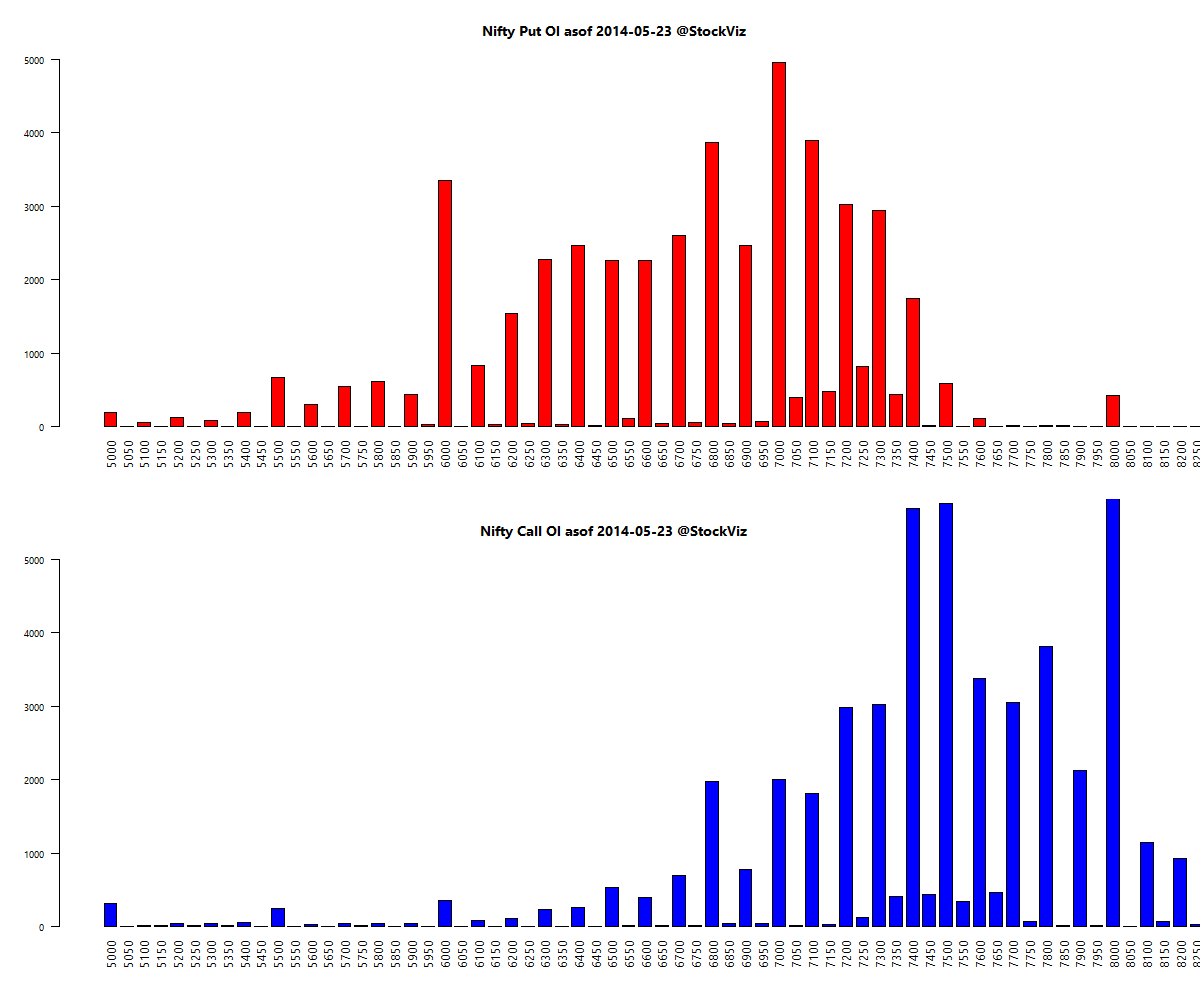
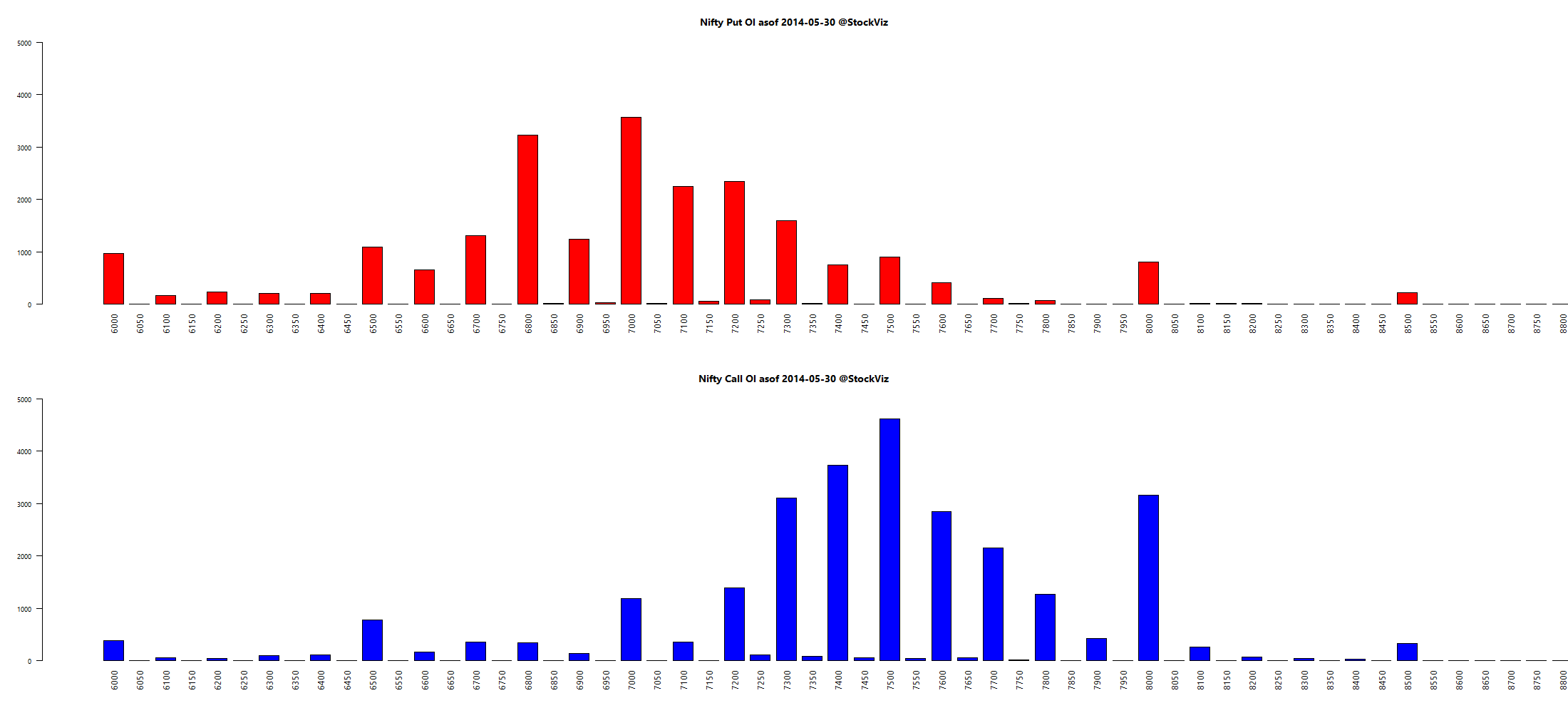
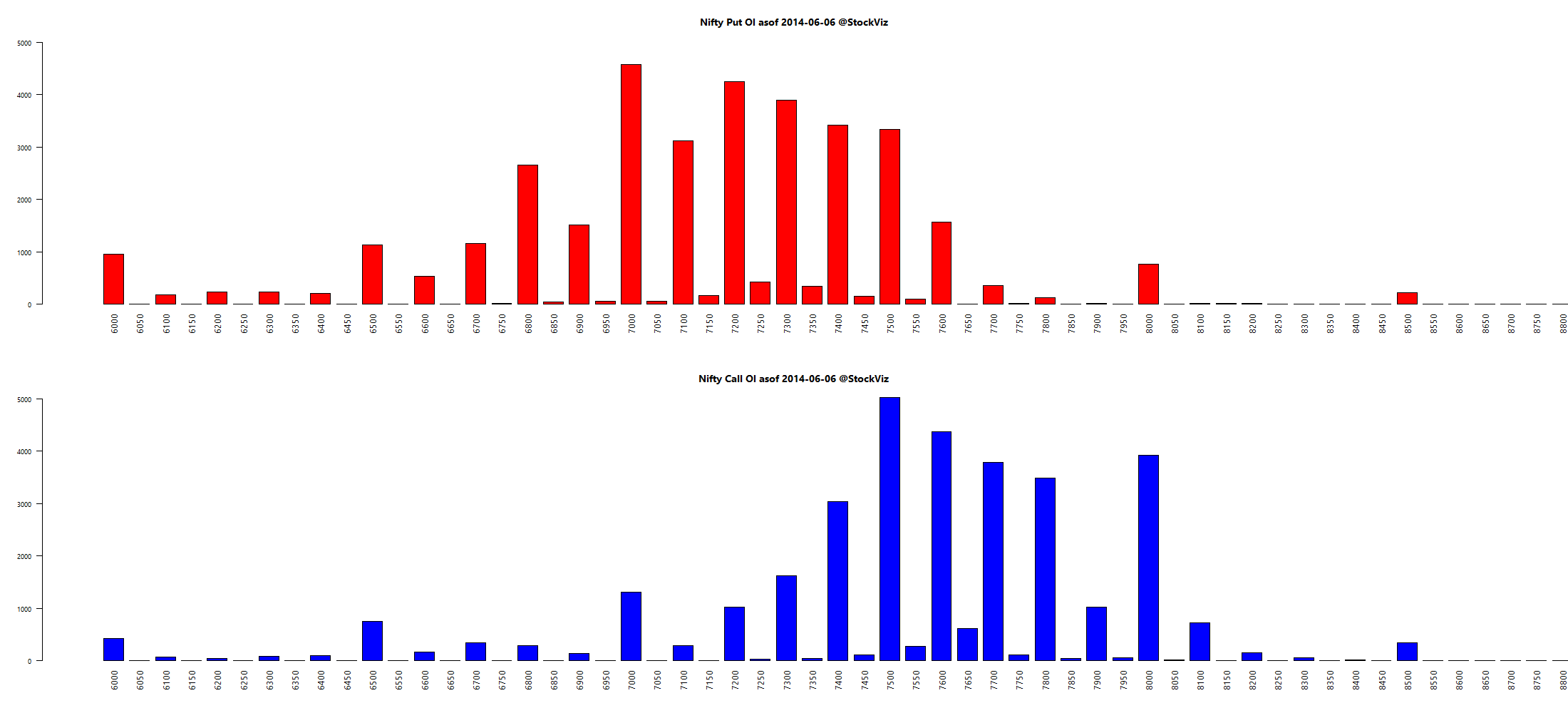
Here’s a telling chart on what investors “thought” they made vs what they actually made:
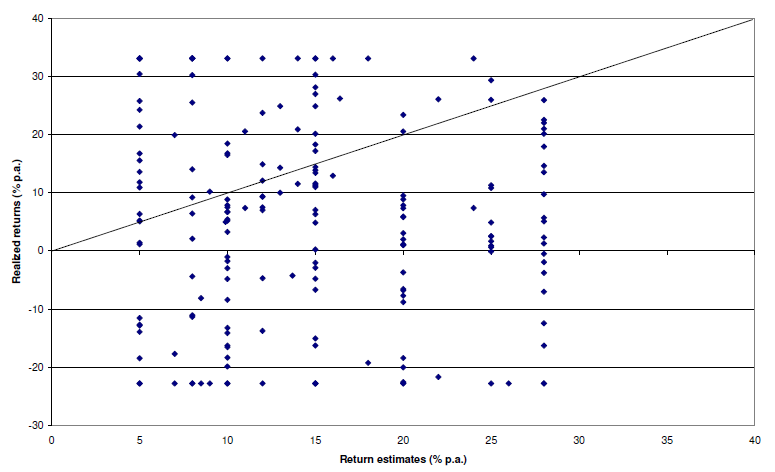
I loved the academic euphemism for “most investors are clueless”: The correlation coe±cient between return estimates and realized returns is not distinguishable from zero. And this gem: The correlation between self ratings and actual performance is also not distinguishable from zero.
Read the whole thing here (pdf) and open a StockViz account and start tracking your portfolio now!